
Tata Steel is Europe's second largest steel producer. Their advanced analytics teams in North Holland work with data to improve the manufacturing processes in the factories, anomaly detection, new product development, and BI/reporting. Data that is being used originates in aggregated and controlled business warehouses, measurements, public data and financial/ERP applications. This data is then used to identify faults in the steel and create ways to increase production, while also saving the company money.
The team’s projects have primarily involved first importing the data from a variety of data sources, and then applying needed transformations in order to produce final applications for consumption. The data was moved around from the original sources to virtual machines at first. But, this way of working raised concerns over scalability and the time spent on each improvement.
Tata Steel hired me, a junior data engineer at Xomnia, to assist in supporting these teams in building a centralized data lake for the needed data. Having a centralized data lake, the data is made readily available in the cloud. I also assisted with the deployment of tools to improve the scalability of the data flow.
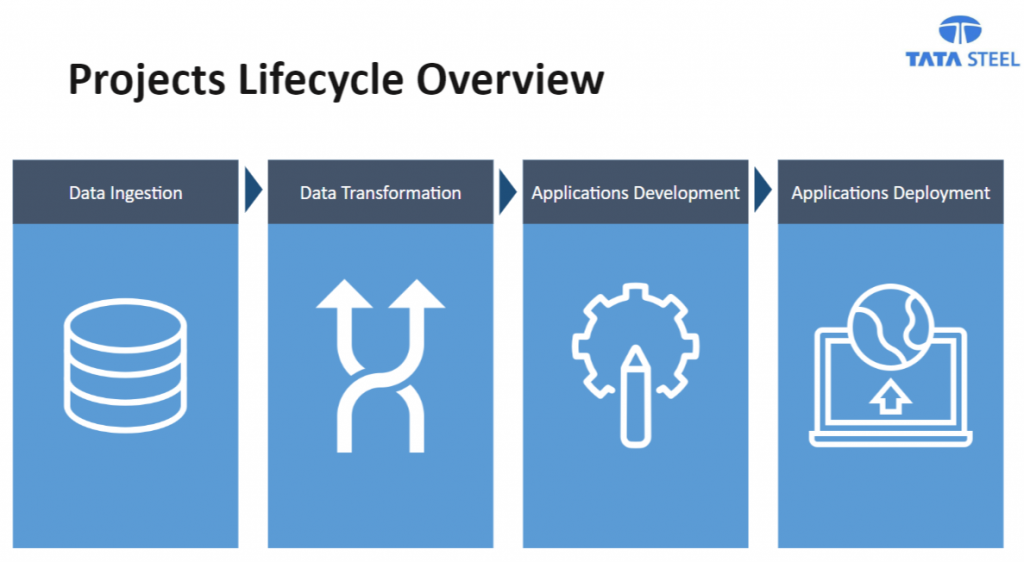
The four steps of each project are: data ingestion, data transformation, applications development and applications deployment.
At the beginning of each project, the project lead on the advanced analytics teams points out which datasets are missing in the data lake, but are required within the team's project. Further details are shared, such as the amount of data (going back weeks/years/…) or who the owner of that data is. They also specify the amount of data they need for their use-case. For example, some use-cases require data from the last 5 months, while others require data from the last 5 years.
Manufacturing data is found in a variety of data sources, including DB2-Mainframe, Oracle, Microsoft SQL, PI and IBA. The data ingestion is performed using a software called Databricks, which extracts the data from the data sources and stores it in the right bucket. This bucket is dependent on the level of confidentiality of the data.
As soon as the data is available at the data lake, the data scientists can start the data exploration, data cleaning and build and test their transformations. This is all done in Databricks as well, using Spark.
When the transformations are completed and the data is ready to be consumed, the data scientists start developing their applications. The most common applications are reporting dashboards and machine learning models. Each team chooses the preferred technology for the application development, but the technologies more widely used are R and Python.
Following the development, the finished applications are deployed on Kubernetes, making use of CI-CD pipelines. The Kubernetes cluster is hosted by Azure and the pipelines created on Azure DevOps.
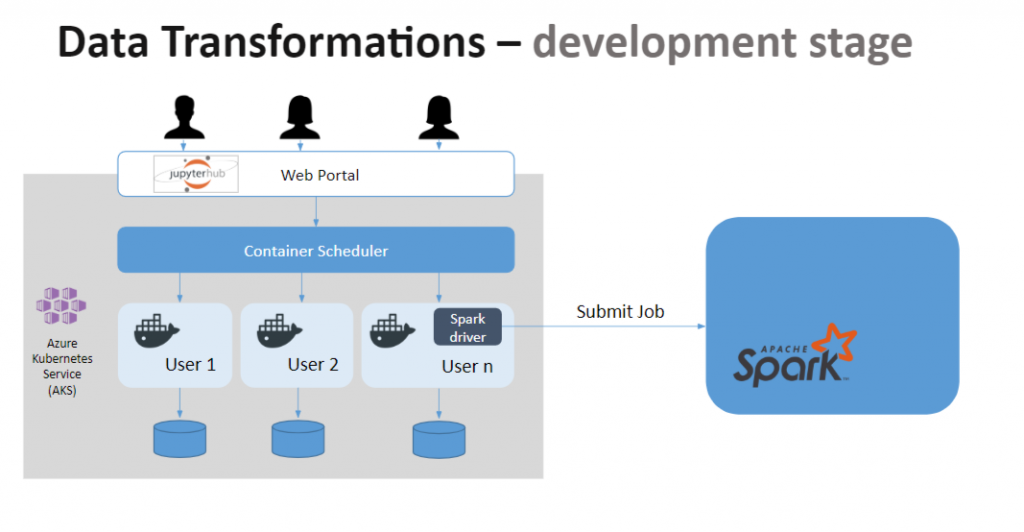
In my role, I support the data scientists during the data transformations and applications deployment. The data transformations can be separated into two different stages. First, the development stage whereby advanced analytics teams explore the datasets and build their transformations.
I worked on creating Databricks clusters in which I pre-installed a set of libraries such as Pandas and Matplotlib. Each team has its own cluster and its own computing resources, and once the cluster is not active, it gets shut down and the resources freed.
Before using Databricks, the teams were using virtual machines. These were on 24/7, therefore costing more than the Databricks solution. Not only is this solution more cost-effective, it is also more scalable. When the servers get shut down, the users’ data is not lost; it is stored in persistent volumes that get attached to a new server when the user starts working again.
The second stage of the data transformations can be called the incremental stage, the point at which the data transformations are already defined and applied to the first batch of data. With new data being added everyday, the transformations need to be applied to the most recent data on a daily basis and appended to the previously transformed data. To schedule these daily transformations, I deployed and configured Airflow, which is also hosted on the Kubernetes cluster.
I configured Airflow to use Celery executor and 3 static worker nodes. The tasks for each DAG depends on each project, but the most common tasks are related to copying the Python script to the Databricks cluster using the SFTP Operator, followed by the use of the SSH Operator to submit the spark job. In this case, the SSH Operator applies the transformations to the data, and either appends the new data to a pre-existing dataset, or overwrites the dataset, depending on the use-case.
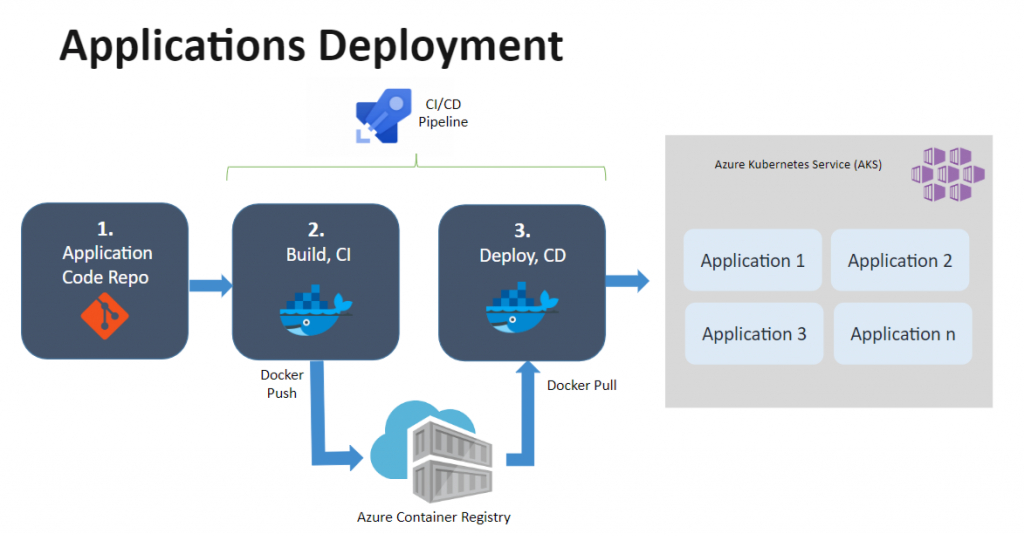
Once the teams are finished with their application, we work together on building a containerized application with docker and adding the final code to a repository. I created the CI-CD pipeline in Azure DevOps, which takes the developed containerized application, builds the image and saves it to the Azure container registry. The second part of the pipeline pulls the image from the container registry and deploys it to the Kubernetes cluster.
With the solution presented above, we managed to improve the whole lifecycle of the advanced analytics projects, not only by the provision of platforms and tools for their work, but also by providing a more scalable solution. As compared to the initial way of working, we eliminated the use of VMs, this way reducing costs.
Even though the solution we have at this moment is already more scalable compared to the initial one, there is still room for improvement. For future developments, we want to enable the auto-scaling feature in Kubernetes, and also use Kubernetes executor instead of Celery executor, in order to save resources and be more scalable.
*****
This blog was written by Nelson Sales, during his junior development program year at Xomnia. He's since been hired by Tata Steel. Are you interested in becoming an expert in data architecture, tools, and technologies, software engineering, and data streaming? If you have a background in computer science or software engineering, you might be a great fit for our one year development program for Machine Learning Engineers. Check out the vacancy and contact us to learn more.

The gap between a compelling GenAI demo and a working production system is wider than most organisations expect. And the reason is almost never the technology.
So you centralise. The right call. One team manages agentic AI. They create rules, stop...

This blog is about getting full control of your data. And it is geared towards data platforms. However, a lot of the more generic remarks will hold up for other types of system environments also.

Modern AI tools have democratized software creation. With the concept of ‘vibe coding’ maturing to ‘agentic engineering’ and some powerful new plugins (or skills, MCP tools and CLI’s), full-stack development is now accessible to a much wider audienc...




