
No terms found for this post.
This blog is the third of a series on AI business problems, written by Xomnia’s Analytics Translators.
Our lead analytics translator Jasper Küller introduced Xomnia’s AI value proposition method in the first of this blog series. He explained the three important questions that need to be answered when defining an AI strategy. Secondly, Analytics Translator Robin van den Brink explained how to match the AI value proposition to the data maturity. Together, they create an AI roadmap.
While the AI roadmap is a valuable asset on its own, it does not answer how to go from idea to developing a data product. In this blog, we discuss how Xomnia gets from an idea to the first development steps in sprint one. We do so by using our use case canvas before sprinting, and by developing the first iteration on the backlog through proven product owner methods. All of these have the purpose of strengthening our way of working.
Building a data product requires a somewhat different approach than, for instance, building a house. When building a house, you want to ensure that you know exactly what type of bricks you are going to use, how big a room should be and where you are going to place the toilet. The waterfall / PRINCE2 method works like a charm for such a project. This is because these types of projects are complicated, but not necessarily complex. Beforehand, you know quite well what the house will look like and what you will need. The steps are clear and so is the order.
The uncertain and complex nature of data products, however, does not allow for such a structured approach. You don’t want to spend a lot of time designing the solution when the likelihood of pivoting the solution after the first few weeks is quite large. This is why most software, including data and AI solutions, are built using the agile scrum framework. However, estimating the complexity for this type of development work is considered difficult, while just starting off development will only result in finding out that there are many impediments that need solving first. So how and where do you start?
For such situations, Xomnia has designed the use case canvas, a one-pager that helps deconstruct the problem, the business case, the end users and other important stakeholders into a simplified overview. Most of this should already be known. As such, it is a follow-up on the ‘what’ question in the value proposition method.
By having an agile software development team, businesses can take advantage of the use case canvas, sprinting, and other product owner methods to move from idea to lift-off in an efficient and structured manner. This process, as outlined here, helps ensure a successful data product development process and that the end product meets the customer's expectations.
The purpose of the use case canvas is to have a quick overview of important aspects of developing a data product, aspects that we at Xomnia consider to be vital for any data product development.
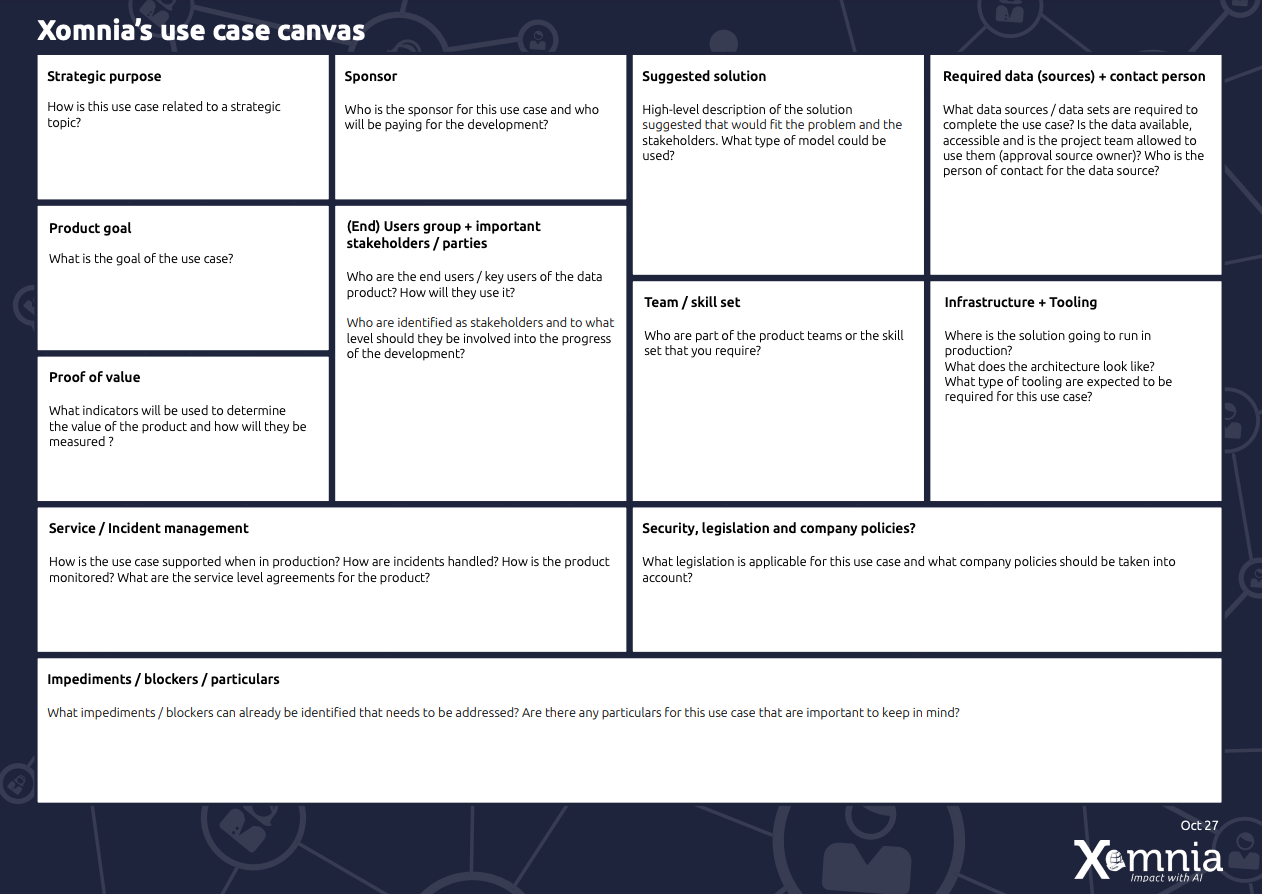
Figure 1: Xomnia’s use case canvas
The use case canvas starts off with understanding where the use case comes from: What is the strategic purpose of the use case, and what strategic topic does it address ? At Xomnia, we have defined four main sources of strategic goals for AI use cases:
In our webinar on how to identify a good data science use case, we zoom in on these strategic goals. It is good to mention that the four sources are not mutually exclusive, which will require more time and energy to fully understand why the use case came to be.
From the origin of the use case, you should be able to derive and understand what the goal of the product is. The product goal is very closely related to the strategic purpose; however, it is shaped on a different level. For instance, if the strategic purpose could be innovation, where the product goal could be to match customers with partner businesses. Knowing what goal and high level strategy are behind the use case can help identify the shape of the solution and project. Once you know the goal of the use case, you will need to start to form a sense of direction for the solution.
The proof of value zooms in on how the goal of the product will be measured. If your goal is to be a matching platform between businesses, your measure of success could be the number of deals that are realized. Designing and determining the measures of success are crucial. These measures will not only be used during evaluation, but also during development. It allows for the data scientists to quickly act on the measurements and make decisions accordingly. We will deep dive further into the proof of value of use cases in one of our future blogs.
The sponsor is the person who will need to budget and pay for the project. It is important to have the name of an individual here and not a department name. You will need to invest more time into your progress update with this person.
A number of items on the use case canvas are related to the stakeholders, end users and owners of the project. You might wonder why, and maybe suspect that the technology would play a larger aspect of a data project. According to Gartner, 85% of all data science projects fail during the initial stages. The number one reason is the absence of available data. However, almost all other reasons are non-technical and focused on organizational and people-related factors: no buy-in from management, end users never use the product, no owner of the product, etc.
For this reason, you want to identify (before starting the development of a product) who are the end-users, who are key stakeholders, who should just inform and who are you reporting to when it comes down to progress and budget. This also allows you to get a clear picture of who you want to invite to your sprint reviews.
While the use case canvas focuses mostly on the problem at hand, this section highlights the suggested solution. The sections should provide a sense of the direction you would like to take with the project. Of course, this can change quite frequently; however, it gives some bearings for the team to find focus. Besides, it will also allow for a validation of the solution concept with stakeholders.
Of course, you cannot move past technology and data. It’s important to identify potential data sources and the type data that you will need. If you require very sensitive data for your project, you can guess that a lot of your time will be consumed by assuring compliance, risk and security that all requirements will be met. However, the main focus for thinking about data sources is to identify potential issues with these data sources. Is the data available? Is it understandable? Of course, you can’t do this for all the data. The idea here is to make sure the most important ones are ready for you to be used.
When moving towards a production (like) environment, you will notice that the work will mostly be shaped by company policies, legislation and processes on supporting the product. Because these items can have quite an impact on the product results, it is important to think about them from the start - especially the operational support side of the product. Often, enough products are developed without the support in mind, causing a lot of manual labor afterwards. Questions to think about include how to retrain the model, who and how are you going to monitor the model, and what happens when someone encounters an issue. Taking some time and putting in some effort now will allow you to reap the benefits later.
During one of my assignments at Xomnia, I was involved in setting up a data product in the cloud. While everything was running smoothly in production, we learned that the company had the policy that all the IT-related developed products needed to be registered in a client owned application so that any issues would be recorded, measured and assigned to the proper team. However, since this was the first data product in the cloud, the client's application was not ready to incorporate this. In the end, the project had to be postponed (taken out of production) until the application was able to incorporate this. These are the things you need to know before and while development, so it can be tackled.
The last section on the canvas is the one concerning potential impediments, blockers or any particulars related to the project. This could be the availability of a certain key department, access to a platform, the use of sensitive data without a secured development environment, and the lack of a specific skill. Items that should be addressed while moving on, as they might not block your development now, but probably will in the future.
With the initial draft of the canvas ready, make sure you validate the use case. Are the key stakeholders indeed involved and do you have their commitment? Another important aspect to validate are the underlying assumptions. Are they supported by the business and key stakeholders? Not validating the solution and assumptions is one of the most fundamental mistakes at the start of each data project.
Once the canvas is completed and validated, you will want to make sure you keep the canvas in a visible spot. This is preferably in a physical area where it can be a constant reminder to you and the rest of the team on what you want to achieve with the project / product, and keep your eye on the desired outcome. Although we are now at the start of the development cycle, the canvas will remain to be work in progress. This means it can and should be adjusted throughout the development cycle, once more information becomes clear.
Now that you have a sense of direction, it is time to take the first steps towards the actual development of the product / project. By this time, you should have a team which is ready to go. Curious what type of roles Xomnia has identified in development teams? Read all about it in our Way of Working whitepaper here.
The further scoping of use cases should not be a showstopper for the start of the development. After the initial refinement through the use case canvas, you can start setting up a high level backlog. From the backlog, the starting grounds should be clear and the first smaller pieces of the puzzle should be identified.
A good first step for development is always to start with exploration by the whole team. Exploration can be done in three different aspects. Three aspects that will remain important for the entire development process: the use case, the data and the infrastructure. The data scientist should start creating a data exploration document, which tells the stakeholders if the datasets and sources provided are good enough to use for the development of the product. Besides giving useful insights to the stakeholders, it also allows the data experts to become familiar with the data.
The engineering expert can start exploring the infrastructure, checking things like team access to the development environment, availability of a test environment, setting up a repo, etc. This also gives the product owner (PO) the time to dig further into the use case to find out the next steps to take by the development team. In this blog, we assume to work according to the agile scrum framework. All sprints should consist of 1) use case refinement, 2) development and 3) operations (necessary when your first deployment has taken place).
Developers might be reluctant to start building iteratively, because it is often perceived as inefficient or even as extra work when the final solution is not crystal clear yet. In practice, however, this is a great way to detect whether the value is real or quickly pivot the problem statement if this is not the case. Moreover, for a data project, it helps to embrace hypothesis driven development. This is because for most data scientists, it is hard to estimate the required work, because of the uncertainty and complexity. Creating hypotheses to focus on and to drill the problem down in smaller pieces helps in dividing the problem and grasping the effects. While this requires a change in mindset, the benefit for a data science project is huge. It can take away some of the uncertainty and even approach the problem more systematically. In addition, hypothesis-driven development allows to ‘more easily’ measure impact and could help with the adoption of the solution. This approach works most effectively for data science projects, but is not ideal for engineering work. Fortunately, estimating the engineering work is easier to do because it has less uncertainty.
To help the PO find and prioritize the first steps in the development process, it can be very helpful to do a 3x3 session. A 3x3 session is a workshop done by the entire team. During this session, you start off by discussing work items that have been identified already for the backlog. After going through each and all of the identified work items, the team will pick up a work item and guesstimates if the work item is small, medium or large. Once all the work items are done, you move on to guesstimate if the work item is small-small, medium-small or large-small. This is repeated for all the sizes -- hence 3x3. This should break down the backlog into different chunks of work and give insights into potential blockers and order. The order is especially interesting for the PO. Giving the entire team an overview of the different components and focus points for the start of the product development.
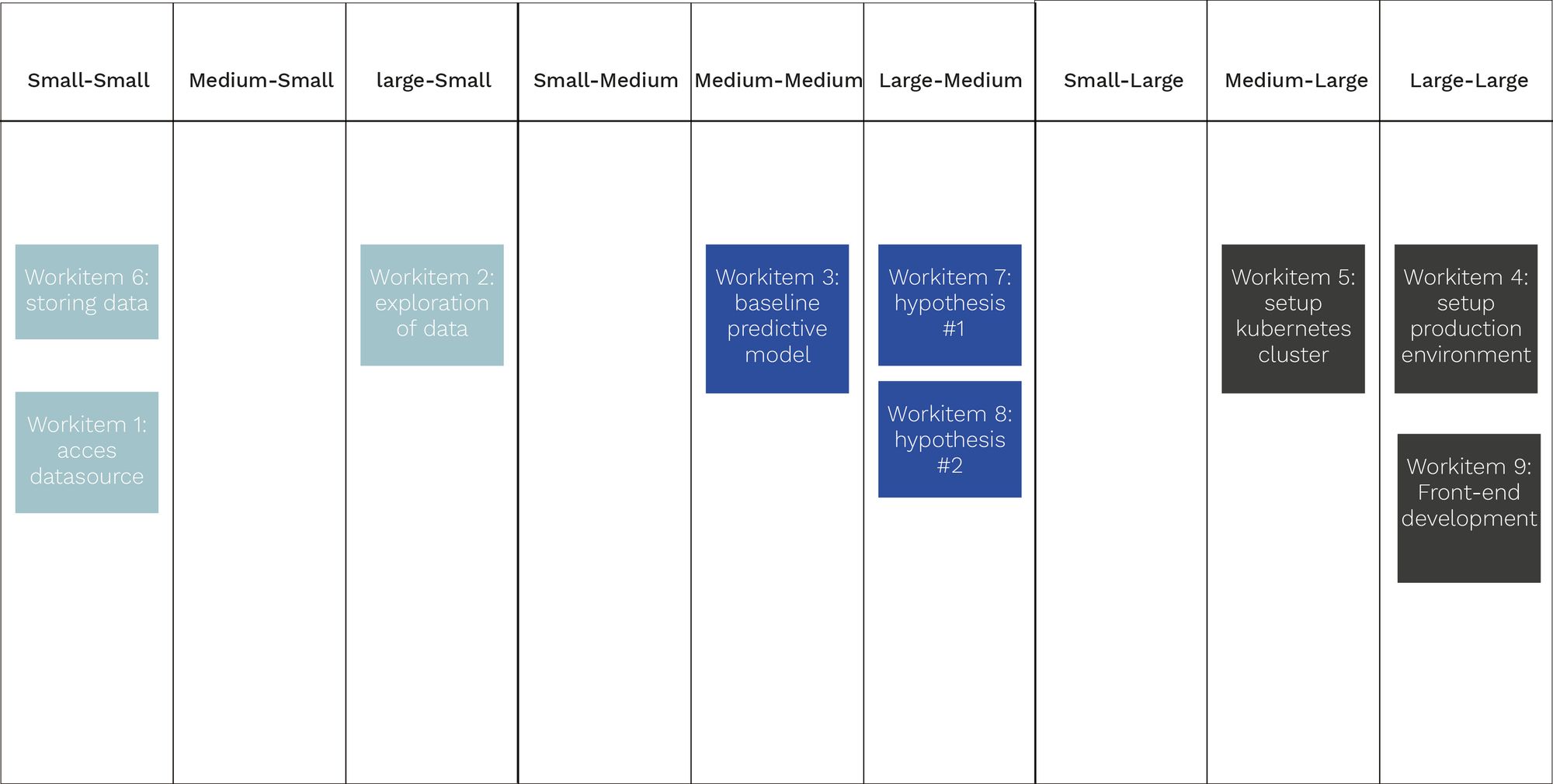
Figure 2: Simplified result of the 3x3 session
With the exploration and 3x3 session done, the PO should have been able to get a good start on the backlog, because the work has been broken down and the PO can prioritize according it’s own estimation of value. From here on the team can start with the ‘regular’ development according to the agreed upon rhythm. During this development, the team will keep on developing the use case and the solution based on the feedback and new insights. The chances are that the team will have to prove the value of the project in an early stage. There are many misconceptions about value when it comes to data products and often enough it is not quite that easy.
Xomnia has worked together with a Dutch insurance company specialized in legal support in creating a data-driven product. In this case, the product was a dashboard that would bring multiple data sources together and provide insights and support in their decision-making process. Together with the business, IT manager and privacy and security teams, a workshop was done to go through the use case canvas. This allowed everyone to be quickly aware of the requirements regarding access to data, access to people and specific company policies. Plus, it gave the development team a good starting backlog. Because of this approach, the team was able to quickly develop the dashboard that was in line with the expectations of the client, also because the prerequisites were clear for everyone.
This approach is also used in the early stages of Xomnia’s spin-off company, Shipping Technology. Shipping Technology is building (semi) autonomous solutions for inland shipping vessels. In the beginning, they were struggling to find a structured approach and to form an initial backlog. The team was overloaded with different ideas and possibilities. After structuring the problem, idea and situation on a use case canvas, the team, including main stakeholders, deep dived with the aid of a 3x3 session. This session did not only form the starting point for the development / backlog, but also showed the stakeholders what actions / activities were needed to create the value they were most interested in. Besides creating a better understanding of the business problems, this also provided understanding for the development process and more engagement from the stakeholders.
—
Xomnia has a team of Analytics Translators (ATs) dedicated to assisting clients with the business aspects of AI challenges. They do so in several roles, such as AI Product Owner (product-focused), AI evangelist (adoption-focused), AI ethicist (responsibility-focused), or Strategic AI advisor (strategy-focused). In this last role, our ATs tackle the first of seven AI business problems (creating a strong AI vision and plan aligned with the overall business strategy - topic of this blog). In our next AT blog, we’ll discuss our proof of value method.
Would you like to learn more or have a conversation about AI business challenges at your organization? Get in touch: info@xomnia.com.
No terms found for this post.

The gap between a compelling GenAI demo and a working production system is wider than most organisations expect. And the reason is almost never the technology.
So you centralise. The right call. One team manages agentic AI. They create rules, stop...

This blog is about getting full control of your data. And it is geared towards data platforms. However, a lot of the more generic remarks will hold up for other types of system environments also.

Modern AI tools have democratized software creation. With the concept of ‘vibe coding’ maturing to ‘agentic engineering’ and some powerful new plugins (or skills, MCP tools and CLI’s), full-stack development is now accessible to a much wider audienc...




