The last decade has been somewhat a golden age for big data and artificial intelligence (AI). Today’s reality is a world where bank fraud is foreseen and prevented, where retail prices are dynamically optimized for the maximum benefit, and where image classification further improves the robotics industry. Data science and artificial intelligence are at the center of progress when it comes to performing successful prediction tasks.
However, companies often make a big mistake when developing AI. If a business focuses too much on creating machine learning (ML) models and too little on actually deploying or maintaining them, they may not achieve their desired results. Here is where Machine Learning Operations (MLOps) fits in: A lot of data projects that lose track would have a much better chance of success if MLOps practices were applied.
In this blog, we will define what MLOps is and where it comes from. Afterwards, we will define the machine learning life cycle that gives a useful set of practices to develop machine learning models into production. Finally, we will define some best practices in the field and explain the benefits of using MLOps.
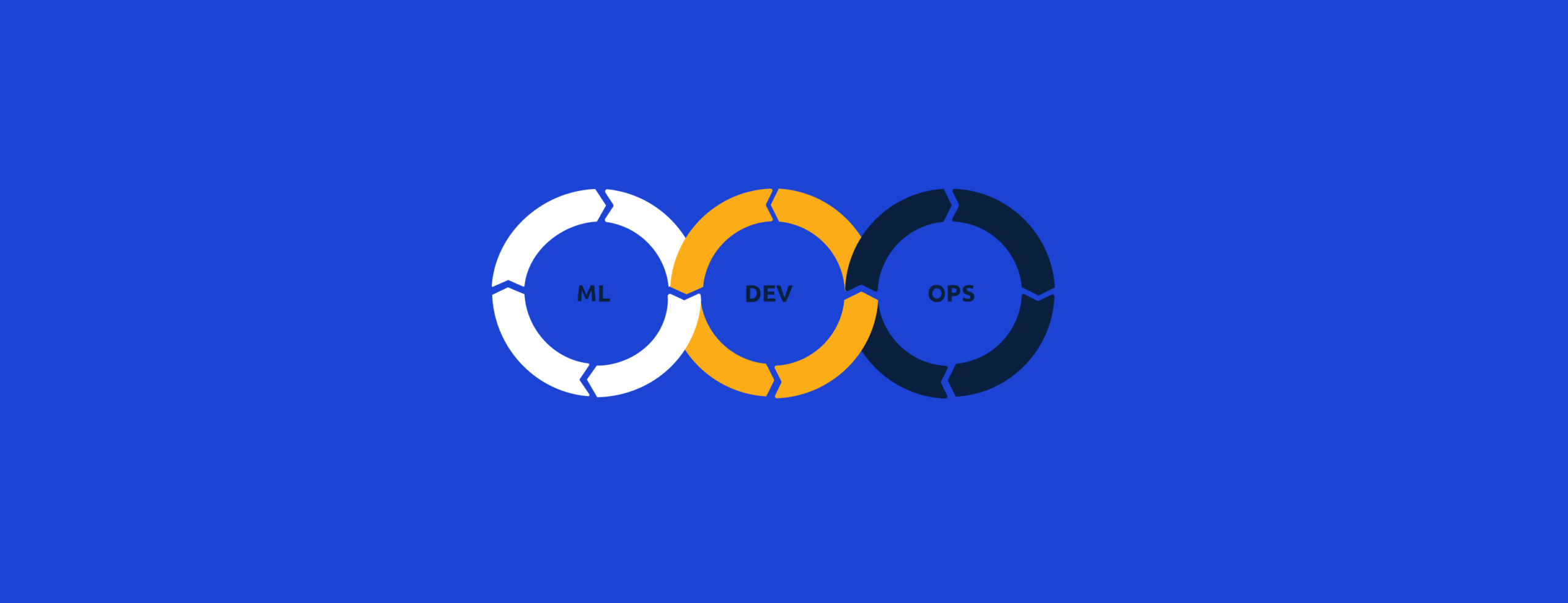
MLOps refers to a set of practices that aims to design production frameworks that can make developing and maintaining ML models fast, seamless and efficient. MLOps is a relatively new term that answers questions like:
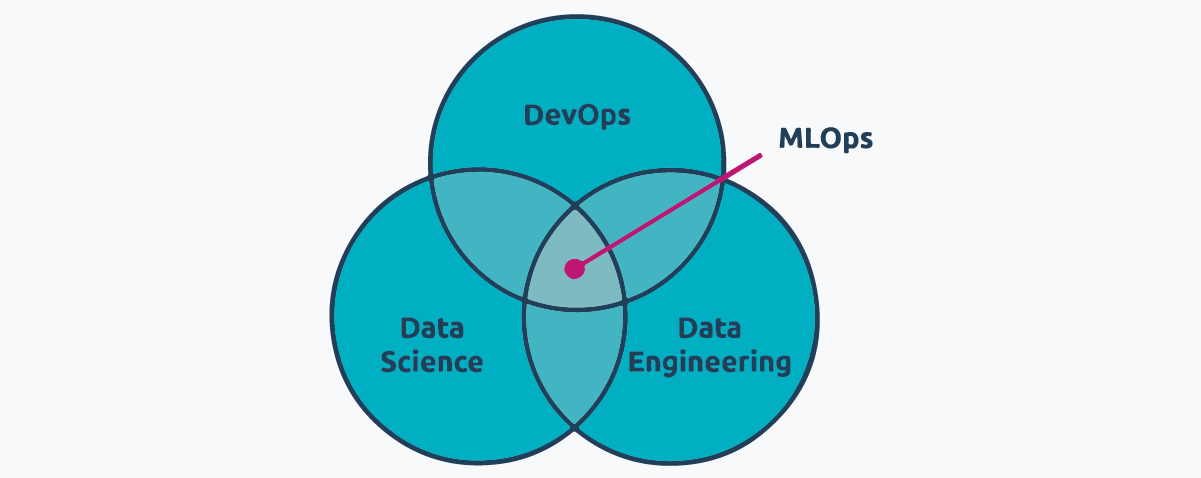
MLOps comes from the necessity to create machine learning models that will be used extensively and, therefore, need a framework to keep them functioning and up to date. For this, MLOps uses a set of practices at the intersection of data engineering, data science and DevOps.
Data engineering practices are aimed to make data easily accessible and clean for machine learning models. Data science skill sets help in creating models, all along the process from design to test. Finally, DevOps practices are used to deploy and monitor these models in an automated manner, so that the model can be improved with newer results or retrained when results deviate from ideal.
However, putting all these practices together in a big bowl and mixing them will not create a good framework. These skills are better explained if we follow the life cycle of a machine learning model.
MLOps comes from the necessity of creating machine learning models that will be used extensively, and, as a result, presents a set of practices that helps productionizing them in a context of system development.
Using MLOps will give you advantages such as:
Xomnia's experts created an MLOps canvas used for describing and visualizing production systems with machine learning. It covers a wide range of aspects that have to be taken into account to sustainably run machine learning applications in production. You can read more about it by clicking here.
Don't miss Xomnia's latest business cases and blogs. Subscribe to our newsletter.
As DevOps defines the systems development life cycle and gives guidelines on how to join development and operations, MLOps defines the machine learning life cycle and builds on top of the DevOps guidelines by adding steps related to ML models. This requires a normative, problem-solving perspective, and a focus on automation and scalability.
The machine learning life cycle can be broken down per the following:
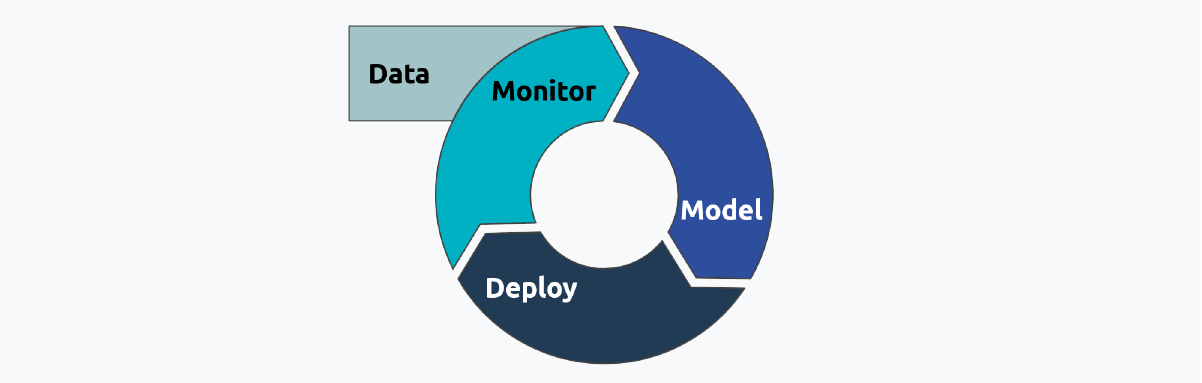
In the following section, we will dig deeper into each of these steps and explain the best practices that will make your ML model shine. Additionally, we will mention tools and frameworks that can help you perform them. However, some of these tools have many more features that may spread throughout the life cycle. Furthermore, there are frameworks that try to incorporate the whole life cycle in one place, such as H2O, ZenML, Databricks, AWS Sagemaker and Azure ML.

All good machine learning models start with good data. To prepare data for an ML model, a series of pipelines needs to be created. These pipelines ensure not only the constant ingestion of the data and its proper cleaning and wrangling, but also, depending on the model, the data can be automatically labeled and split into training, validation and test sets.
Moreover, exploration and validation of the data needs to be performed. Exploration will show you the data structure and its content, while validation is important to ensure the data quality. This can be done by applying specific tests that the data needs to pass. This is further explained in the monitoring step, since it is the closing step of the machine learning life cycle.

Once the data is ready, a machine learning model needs to be selected and optimized. This requires experimentation on different models and on different hyperparameters within a model. To ensure reproducibility, these experiments are stored in a registry where tags are allowed in order to select the desired ML model that will be used for the next step.
Each experiment has 3 main components fundamental to the data science development:
Keeping the registry of experiments not only ensures reproducibility and scalability, but also ensures governance and regulatory compliance. When using ML models, it is important to be able to show which code was used for the model, when it was trained, with which data set and parameters it was trained, which tests did it pass or fail and who is responsible for it. This registry can be kept at frameworks such as ML Flow, Neptune and Weights & Biases.
Once the model passes all the tests, it can be taken into production. For this, MLOps uses similar guidelines than DevOps, since the model can be seen as a system or application. During this stage, the model will be configured and prepared so the end-user can access it.

To deploy a machine learning model, it needs to be first properly packaged for usage. It is important to save within the package all necessary information of the model, such as the code version, model version, data that was used to train the model, and additional metadata necessary for governance and legal requirements. After obtaining the package, it can be deployed so it reaches the end-user. The specifics of the packaging and deployment depend on each use-case and for it there are a variety of frameworks available such as BentoML, Seldon or Kubeflow.
After deploying an ML model, a good MLOps framework should be able to constantly monitor how the model and system performs. Monitoring is embedded in all engineering practices, and MLOps is no different. Not only monitoring the expected behavior, but also setting standards that models should adhere to, is fundamental to MLOps.
Some metrics that need to be checked when monitoring a machine learning model include:
Moreover, a detection system can be built on top of the metrics in order to automate model retraining. For example, if the model starts to drift, the system can trigger a retrain process. Furthermore, if the system or application changes its need regarding storage capacity or computational power, the model can be scaled up or down. Some tools that can be used to monitor both the model and the data are Arthur, Arize, Comet, Evidently and WhyLabs.
The monitoring step closes the life cycle of machine learning by reincorporating feedback into the model and deployment.
Don't miss Xomnia's events, which focus on the latest trends in the world of AI. Click here.
Continuous Integration and Continuous Delivery (CI/CD) are among the core pillars of DevOps and thus also MLOps development. With MLOps, one can implement new features and upgrades into the solution while at the same time having checks if those modifications are compatible with the running model to avoid its disruption.
To implement CI/CD in MLOps, the following tests are useful:
Though version control for code is standard procedure in software development, machine learning solutions require a more involved process. This entails versioning the following artifacts:

The gap between a compelling GenAI demo and a working production system is wider than most organisations expect. And the reason is almost never the technology.
So you centralise. The right call. One team manages agentic AI. They create rules, stop...

This blog is about getting full control of your data. And it is geared towards data platforms. However, a lot of the more generic remarks will hold up for other types of system environments also.

Modern AI tools have democratized software creation. With the concept of ‘vibe coding’ maturing to ‘agentic engineering’ and some powerful new plugins (or skills, MCP tools and CLI’s), full-stack development is now accessible to a much wider audienc...




