
Throughout my experience as a data engineer, I’ve noticed that most data engineers will opt for Redshift, the (familiar) AWS native solution, without thinking about giving its alternatives a chance.
Redshift is one of the first cloud data warehouse services. Compared to on-premise data center solutions, it is fast, cheap, and overall great. However, times change, and the year 2014 is well behind us, which really calls to consider more modern options too, like Amazon Athena.
Like Amazon Redshift, Amazon Athena is a powerful tool for managing data in the Amazon Web Services (AWS) cloud. Both tools are popular choices for data warehousing and analytics, and each has its own unique strengths and capabilities.
In this blog, I will compare Athena and Redshift, and explore why Athena may be the superior choice in an AWS data platform. I will also compare Athena to other popular data warehousing solutions, including Google BigQuery, Azure Synapse Analytics, and Snowflake.
Amazon Athena is a serverless query engine based on Presto that allows users to run SQL queries on data stored in S3. It is designed to be easy to use and supports popular SQL clients. Athena is ideal for running ad-hoc queries on large amounts of data, exploring and analyzing data without the overhead of setting up and maintaining a separate data warehouse.
Not setting up a separate data warehouse (DWH) is why AWS calls these “ad-hoc queries”. It supports both batch and streaming data sources, making it a good choice for querying constantly changing data. Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data.
AWS Glue is an ETL (extract, transform, and load) service provided by AWS. It simplifies the process of discovering, categorizing, and cleaning data from various sources, such as S3 and relational databases, and makes it easier to integrate the data into data lakes and data warehouses. The service also enables users to define and enforce schema and data quality rules. AWS Glue provides a scalable and cost-effective way to prepare and transform large volumes of data for downstream processing and analysis.
Together, AWS Glue and Amazon Athena can be used to extract, transform, and load data from various sources into S3, and then run SQL queries on that data using Amazon Athena. While it's common to use Python for ETLs rather than AWS Glue due to cost and flexibility concerns, the Athena + Glue Data Catalog combination is still a good choice for users who need to run ad-hoc queries on large amounts of data or explore and analyze data without setting up a separate data warehouse.
Join the leading data & AI consultancy in the Netherlands. Click here to view our vacancies
Accompanying this blog is a repository: Github: Athena vs Redshift. The code snippets mentioned here are from this repository, and you can copy the repository to try it for yourself.
Athena, as mentioned before, uses the data catalogue created by Glue to run. In the following example, I have set up an s3 bucket with data files. These data files are found in the repo, path ./data, and created using drawdata.xyz .
I wanted to show you the easiest use case, which is combining the results of similar data files into a single table. Using a Glue Crawler, we can automatically discover and update the table in the Glue catalogue:
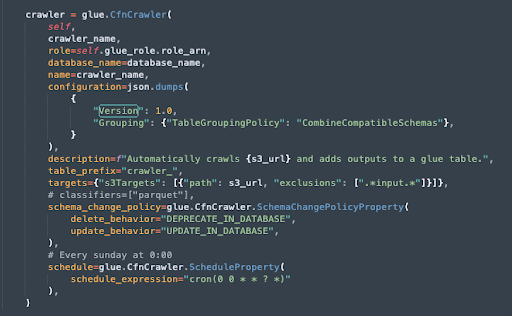
The Glue crawler created above (in AWS CDK) has a number of parameters. It will have a construct name, and a role to use that is created in the same stack. In its configuration, you see that we’ve enabled a TableGroupingPolicy so that it groups (combines) compatible schemas. All tables will have a prefix, _crawler, and we exclude files that have the word input.
Athena supports many database connections when you want to access it from your code. The cleanest way is to use boto3, but many reported success by using a normal database connector. For BI solutions, such as Redshift, connectors are available.
When the use-case is a simple query or exploration, you can access Athena via the AWS web console. If you’re wondering how to set up a user for Athena, the code for creating a role is in the accompanying repository. A user with that role should suffice. Otherwise, it is mostly a normal IAM user that you want to create.
A word of caution about the Glue crawler and its table grouping policy (which is not particularly intelligent, and I’m hoping AWS updates this):
The exclusion here is done _before_ it combines the tables. Sadly, it does not exclude the tables being crawled. In one of my projects, we had a directory that contained Excel sheets and parquet files. I tried to combine them both, because the pattern matched only selected parquet files but the resulting schema just pointed to the folder on S3. The only way we found to fix this was to separate the files in S3 by putting the parquet files into another folder.
We deprecate tables in the database if they are deleted, and update if they’re changed. Finally, we run this crawler every Sunday.
In conclusion, the way to set up your bucket is ideally to create separate folders within the bucket for different tables, and then group them together with a Glue crawler.
Join Xomnia's Data & Drinks events about the latest trends and news in the world of AI. Click here.
Initially, AWS offered their database service (RDS), which was primarily designed for transactional workloads. However, this did not fit the need for (cloud) data warehouses, and as a result, AWS designed Redshift, which became generally available in 2013.
Amazon Redshift is a fully managed data warehouse service that allows users to store and query large amounts of data using SQL. Redshift is based on PostgreSQL, and supports both standard SQL and PostgreSQL-specific extensions. It is designed to be scalable, with support for scaling up and down as needed. Redshift has been a staple of AWS data platforms since its release, to the point where alternatives aren’t even considered by many teams.
Redshift is a good choice for users who need to store and query large amounts of data, and who need a high-performance data warehouse solution. When the workloads join many tables together, the “data warehouse service” power will show itself against the columnar storage method of Athena.
However, Redshift is not fit for ad-hoc requests. It is made to build data warehouses, to have elaborate data models and so forth. Another limitation is that its speed is bound by the compute power you reserve for it, although this does limit the total cost of using it (Athena, on the other hand, is paid by query amount).
Let’s run over a few of the advantages of AWS Athena:
Don't miss Xomnia's latest business cases and blogs. Subscribe to our newsletter.
In addition to comparing Athena and Redshift, it's also important to consider how Athena compares to other popular data warehousing solutions, such as Google BigQuery, Azure Synapse Analytics, and Snowflake:
Join our team of top-talent data and AI professionals. Click here to view our vacancies.
While Redshift and other data warehousing solutions may have their own strengths and capabilities, they may not be as well-suited to certain types of workloads or use cases as AWS Athena. For users who need to run ad-hoc queries on large amounts of data, or who need a simple and cost-effective data warehousing solution, Athena may be the superior choice in an AWS data platform.
Athena's serverless architecture, support for a wide range of data formats and sources, integration with other AWS services, and high performance make it an attractive option for users who need to manage and analyze data in the AWS cloud.
When comparing AWS Athena to other data warehousing solutions, such as BigQuery, Synapse Analytics, and Snowflake, we found that each tool has its own unique strengths and capabilities. Depending on your specific requirements and use case, one of these other tools may be a better fit than AWS Athena or Redshift.
It's important to carefully evaluate your needs and requirements, and to choose the data warehousing solution that best fits your specific needs. Xomnia can provide data architects and engineers with architectural help, in addition to our experience of implementing data platforms.
Note: OpenAI’s ChatGPT was used to generate some of the source material for this blog.

The gap between a compelling GenAI demo and a working production system is wider than most organisations expect. And the reason is almost never the technology.
So you centralise. The right call. One team manages agentic AI. They create rules, stop...

This blog is about getting full control of your data. And it is geared towards data platforms. However, a lot of the more generic remarks will hold up for other types of system environments also.

Modern AI tools have democratized software creation. With the concept of ‘vibe coding’ maturing to ‘agentic engineering’ and some powerful new plugins (or skills, MCP tools and CLI’s), full-stack development is now accessible to a much wider audienc...




