
Do any of the following scenarios apply to you?
If you can relate to these situations, or similar struggles with scalability, maintainability and usability of your data, here’s some great news for you: The transaction storage layer called Delta Lake has the potential to resolve these issues.
Delta Lake was introduced as an open-source storage layer that brings ACID (atomicity, consistency, isolation, durability) transactions to Apache Spark™ and big data workloads.
On its launch in 2017, Delta Lake was centered around Apache Spark, but has since gotten a lot more reach with connectors to other big data frameworks. These include SnowfLake, Apache Flink, Apache Hive, Apache Presto, Azure Synapse, AWS Redshift, Databricks and LakeFS, with Google Bigquery support also launching soon. Furthermore, there are native integrations with brokers (Kafka, Pulsar), and data analytics tools (DBT, PowerBI).
Data governance solutions are seamlessly integrated with Delta Lake. There are Delta connectors for Unity Catalogs (Databricks), AWS Glue or Azure Purview, which allow documenting and sharing data lineage and definitions across organizations.
Delta Lake integrates smoothly with your current data lake solution and enables developers to spend less time managing partition control. Also, since the data history will be stored, it is much simpler to use the data versioning control layer to apply updates and deletions to the data and support the physical data lineage.
Join the leading data & AI consultancy in the Netherlands. Click here to view our vacancies
Delta Lake offers ACID transactions via optimistic concurrency control between writes, which means:
Delta Lake uses Bronze (raw), Silver (clean) and Gold (aggregated) data layers to establish version control of the data. This is because historical storage of the data makes it possible to identify the data changes, audit it and roll back the data version in the past if necessary.
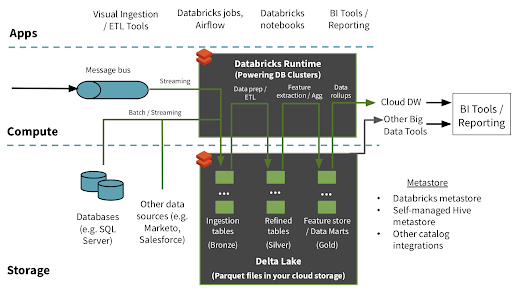
Some of Xomnia’s biggest clients use Delta in production, such as major retail chains selling fast-moving consumer goods, which use Azure / Databricks and AWS / Redshift for their data lake solutions.
Don't miss Xomnia's events about the latest trends and news in the world of AI. Click here.

Data lakes typically have multiple data pipelines reading and writing data concurrently. Data engineers have to go through a tedious process to ensure data integrity, due to the lack of transactions in traditional data lakes. Delta Lake brings ACID transactions to your data lakes. It also guarantees serializability, which is the strongest isolation level.
In big data, even the metadata itself can be "big data". Delta Lake treats metadata just like data, leveraging Spark's distributed processing power to handle all its metadata. As a result, Delta Lake can handle petabyte-scale tables with billions of partitions and files at ease.
It captures all update, append, and delete events on your delta table, including metadata of the change such as date changed. This unlocks further use cases such as a more detailed audit trail or business initiatives, requiring a full history of a single entity (i.e., an order creation journey or a clickstream). This change data feeds can also be sent downstream to a message broker (Kafka, Pulsar), a database of your choice or another Delta table.
Delta Lake provides snapshots of data, enabling developers to access and revert to earlier versions of data for audits, rollbacks or to reproduce experiments. It's already designed with GDPR in mind - running deletes concurrently on older partitions while newer partitions are being appended.
All data in Delta Lake is stored in Apache Parquet format, enabling Delta Lake to leverage the efficient compression and encoding schemes that are native to Parquet. As a bonus, this also entails that Delta is cloud agnostic, so that your Delta implementation can live on AWS (S3 as backend), GCP (Google Cloud Storage), Azure (Data Lake Storage) or on premise.
A table in Delta Lake is both a batch table, as well as a streaming source and sink. Delta tables can ingest streaming data and do batch historic backfills while also offering interactive queries out of the box.
Delta Lake provides the ability to specify your schema and enforce it. This helps ensure that the data types are correct and required columns are present, preventing bad data from causing data corruption.
Big data is continuously changing. Delta Lake enables us to make changes to a table schema that can be applied automatically, without the need for cumbersome DDL. This feature is essential to allow changing data structures and new data use cases in your organization.
Delta Lake transaction log records details about every change made to data providing a full audit trail of the changes. Enabling the CDC feature will allow users to stream changes to other data sources so that the audit trail can be easily queried.
Developers can use Delta Lake with their existing data pipelines with minimal change as it is fully compatible with Spark, the most commonly used big data processing engine.
Although Delta Lake is being adopted by many companies, it is not the only solution that can power your data Lakehouse.
If your organization is already deeply integrated with the Apache suite (Airflow, Spark, Hive, Flink, Presto, Kafka), Apache HUDI has much of the functionality Delta has to offer. This includes lightning fast transactional upserts and deletes, time travel, 100% Spark compatibility, CDC streams, schema evolution and enforcement, and metadata management.
Lastly, another Apache offering, Iceberg (initially developed at Netflix) might also be a good option if you’re looking to support more storage formats besides parquet (i.e. Avro and ORC) while also supporting many of the HUDI and Delta features.
If you’re interested in setting up your own Data Lake / Data Warehouse / Data Lakehouse, get in touch with Xomnia's team of data engineers by clicking here.
This blog was written by Marcus Azevedo, an ex-data engineer at Xomnia, and was updated by our Data Engineer Vincent Roest and Machine Learning Engineer Romano Vacca. We’re on the lookout for another data engineer to join our team. Are you deeply interested in Spark, Kafka or architecting highly scalable distributed systems using different open-source tools - like Delta Lake? Then check out our vacancy and get in touch with us today.

The gap between a compelling GenAI demo and a working production system is wider than most organisations expect. And the reason is almost never the technology.
So you centralise. The right call. One team manages agentic AI. They create rules, stop...

This blog is about getting full control of your data. And it is geared towards data platforms. However, a lot of the more generic remarks will hold up for other types of system environments also.

Modern AI tools have democratized software creation. With the concept of ‘vibe coding’ maturing to ‘agentic engineering’ and some powerful new plugins (or skills, MCP tools and CLI’s), full-stack development is now accessible to a much wider audienc...




