
No terms found for this post.
No terms found for this post.
The success of a machine learning project often relies on the availability of good-quality labeled data. Data labeling in machine learning engineering refers to the process of assigning values to the data points in a dataset to separate them into distinct categories. This division into categories helps to distinguish between different groups of data points and shows which data points are expected to behave or look similar to each other.
The reason that labeled datasets are important for machine learning models is that those models learn by seeing examples of the data, and both the number of examples and their quality make a difference in how well the model learns. For this reason, putting effort into obtaining a large number of examples of data with corresponding labels can be of big help in training your machine learning model.
This blog below aims to explore the following common problem: How to turn an unsupervised problem into a supervised one when labeling is difficult? We will discuss the key to answering this question: Finding a way to use our available business knowledge in the most efficient way.
The traditional data labeling approach can be quite difficult in practice. This is because it often requires domain knowledge and lots of time to go through every single point in the dataset and assigning labels to them.
The difficulty of the traditional data labelling approach lies in adapting to changing situations when labelling, as new data and changing data distributions require starting up the labeling process again to carefully collect a representative labeled dataset. Moreover, the labeling task needs to be precisely defined to the corresponding problem and solution approach, so these need to be accurately defined at the start of the project and cannot be changed easily. Furthermore, domain experts might have conflicting ideas about the underlying process and produce different labels for certain data points.
For instance, have a look at the following example of a satellite image:

Let’s assume that our goal is to identify individual tree species. Then the labeling task for this problem would involve the identification of all the different tree species by a domain expert. These are all marked in this image by different colors.
This can be a quite tedious task that takes a significant amount of time. Image resolution and quality can make it difficult to quickly determine the right category. Tree experts might disagree on what distinguishes certain trees and where to draw boxes around the trees. Therefore, it might be too expensive to label the whole dataset this way.
A common solution is to outsource the labeling task to external parties; however, privacy constraints might limit the possibilities to do this, for example in medical applications.
Join the leading data & AI consultancy in the Netherlands. Click here to view our vacancies
The process of using labeled data points as examples for a machine learning model is called supervised learning. The labels provide supervision to the model by telling it how the data points are grouped. For full supervision, a complete data set is needed with accurate labels. For full supervision, a complete dataset with accurate labels is needed.
There are many alternatives to the traditional, fully-supervised learning approach with individually hand-labeled data points. Those include: transfer learning, unsupervised learning, semi-supervised learning and self-supervised learning.
Two other common approaches are:
Weak supervision is a technique that allows you to quickly generate labels for a large number of data points at the same time. Instead of looking at individual points, you write a set of functions, known as labeling functions. These can be applied to the unlabeled data and their outputs are weak labels, i.e. less accurate or noisier labels. This programmatic approach to labeling makes it much easier and cheaper to obtain large datasets.
Once a set of labels has been defined, the next step is to learn how to combine them into a single label. This is done by learning a label model: a generative model that learns how to estimate the true label (which we don’t know since we’re not labeling manually) by making use of the correlation structure between the labeling functions.
The outcome is a set of probabilistic labels, which are estimates of the conditional distributions of the true label, given values of the weak labels.
The labeling functions can be based on a variety of different sources. This makes it a flexible method to combine all sources of information that are relevant to your problem into one label. A common source is a piece of business knowledge that is captured into a heuristic defined by the expert. Other sources include outcomes of models trained for similar problems (like a transfer learning setting) or external knowledge bases that can be used to create imprecise or partial labels.
Don't miss Xomnia's latest business cases and blogs. Subscribe to our newsletter.
To explain how the weak supervision pipeline works, we’ll use a simple artificial data example where the points belong to one out of two classes:
The pipeline then looks like this:
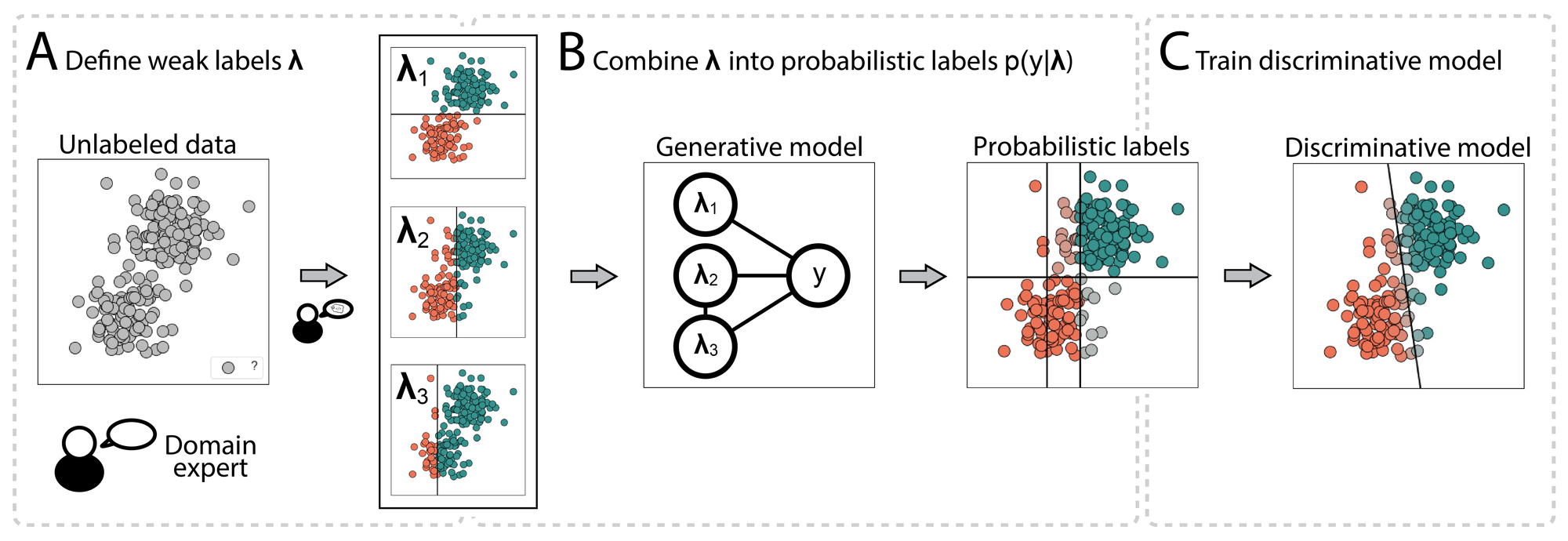
A) Start with an entirely unlabeled dataset: The first step is then to let the domain expert define a set of labeling functions, which are functions that divide up the problem space in our simple example.
B) Combine resulting weak labels: This is done by learning the (generative) label model. This model gives us probabilistic labels as output.
C) Use probabilistic labels as supervision: This final step is done to learn a discriminative model. This can be your typical classification model. However, the loss function may need to be adapted to be able to deal with confidence levels of the labels as output.
The idea of programmatic weak supervision was introduced by the Snorkel project (see the paper and library).
Since its introduction, there have been several examples of the successful application of weak supervision in industry. For example:
Don't miss Xomnia's events, which focus on the latest trends in the world of AI. Click here.
Semi-supervised learning lies between unsupervised learning and supervised learning. The general idea is that you have a small labeled dataset to learn from, as well as a larger unlabeled one that you want to extract additional information from. Generally, this method is based on the idea that points that are closer together in some representation space are more likely to belong to the same class. This sounds similar to weakly supervised learning: you make use of some structure in the data to group points together.
In weak supervision, however, we do not use individually labeled points to create labeling functions and separate the data points. The method also doesn’t necessarily make use of the data density to assign the same weak labels to similar points.
Active learning is an approach that helps you find the most informative points in your dataset in an iterative manner. It makes use of a query strategy, which is a function that computes the potential value of labeling for each point in a pool of unlabeled data points.
This strategy is often based on uncertainty of the model. For points that are closer to the decision boundary of a classification model, the model is less certain about the class. You get more information by labeling these points than you would for labeling points for which you’re already quite certain about the class.
Overall, this approach helps to limit the total number of data points needed to label. However, active learning might still require many labeled points to get sufficient performance. Therefore, this approach on its own might not be a suitable way to get a good dataset for your problem.
The success of label creation with weak supervision relies on the ability of domain experts to define good heuristics. Since the starting point is usually an unsupervised problem, however, it might be difficult to assess the accuracy and quality of the set of weak labels that are being created.
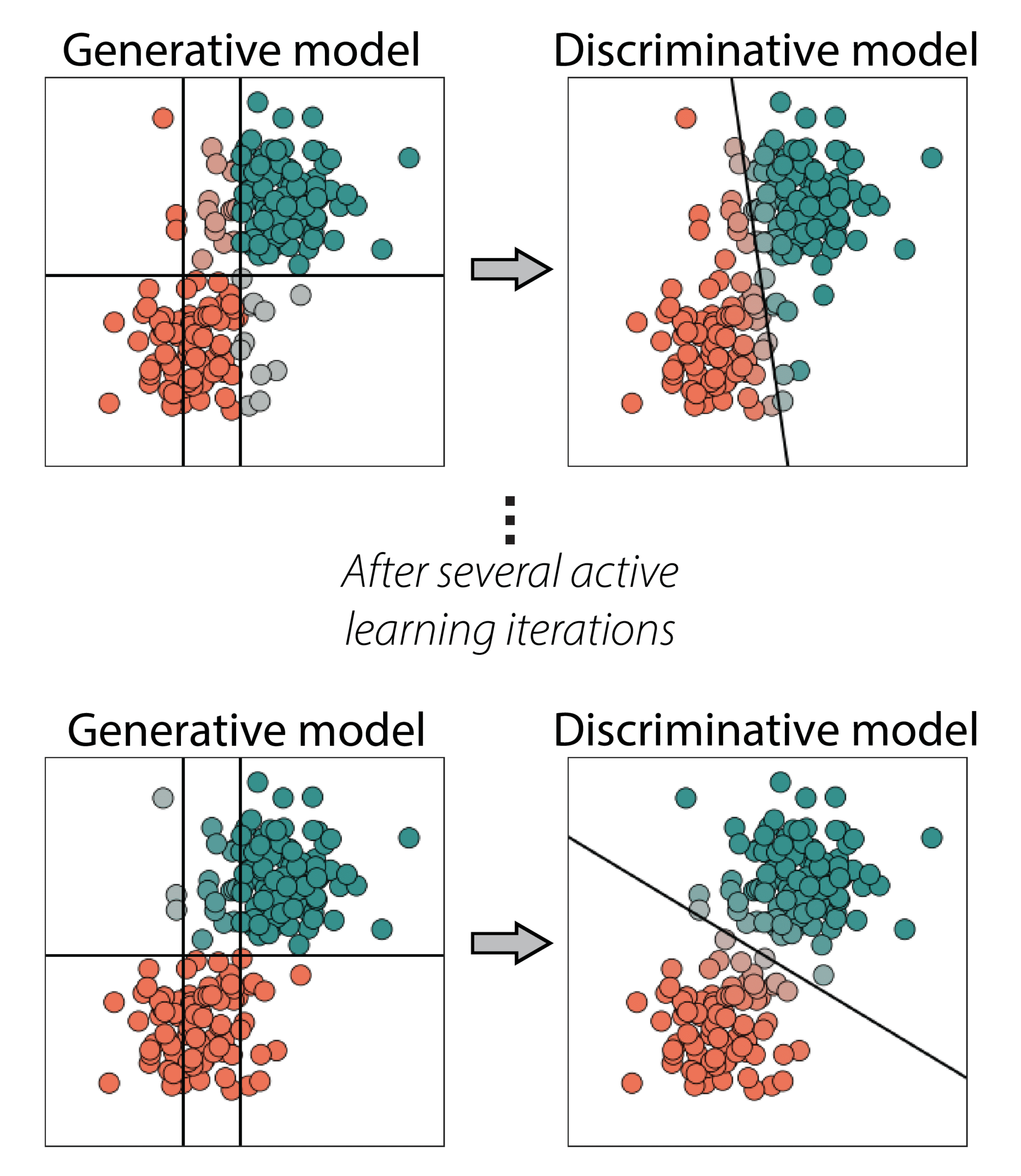
As a result of this challenge, the probabilistic labels resulting from the weak supervision process may be inaccurate. This limits the performance of the final classifier. To see how, let’s revisit the final step of the weak supervision pipeline on the left in the picture below. Because of the suboptimal labels from the generative model, the classification boundary is slightly rotated when compared to the optimal one on the right.
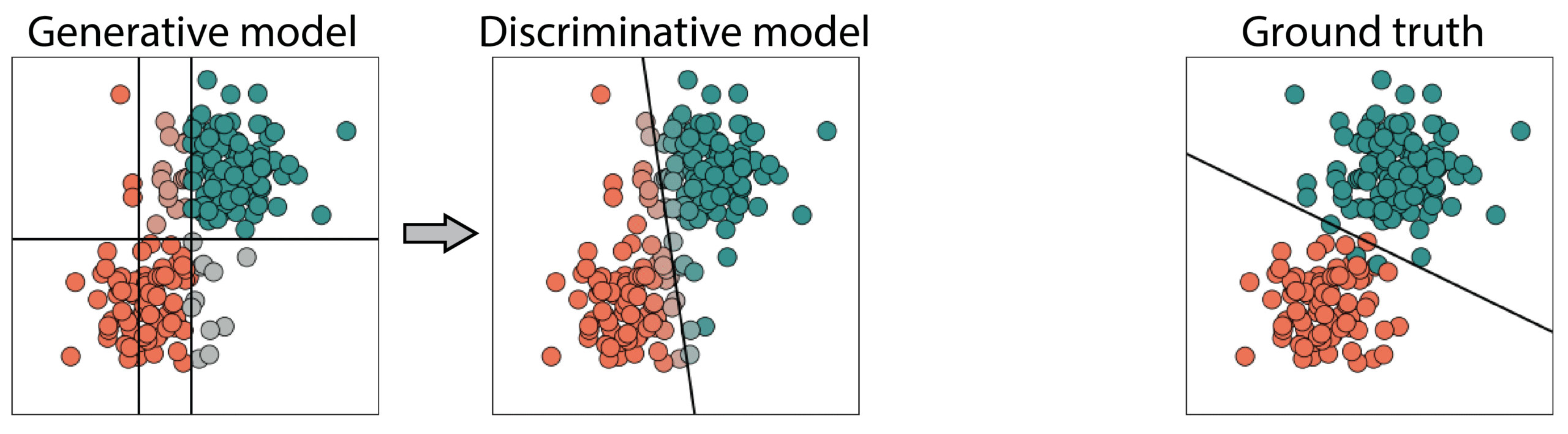
To overcome the challenges of applying weak supervision, it can help to add in an additional type of domain knowledge: a few labeled data points that push the label model to create labels that better represent the data distribution. This idea is implemented in Active WeaSuL through incorporating active learning into the weak supervision framework. The labels that are acquired through active learning provide feedback on how the probabilistic labels from weak supervision perform.
The method works as a loop where you iteratively pick a data point and use it in the label model, which is shown in the figure below. Starting from the initial probabilistic labels, you first choose a point for which it would be most useful to get the true label. This is done by using a sampling strategy (1. MaxKL sampling). Then, the domain expert provides the label, and this new label is used to adjust the generative model (2. Modified loss function).
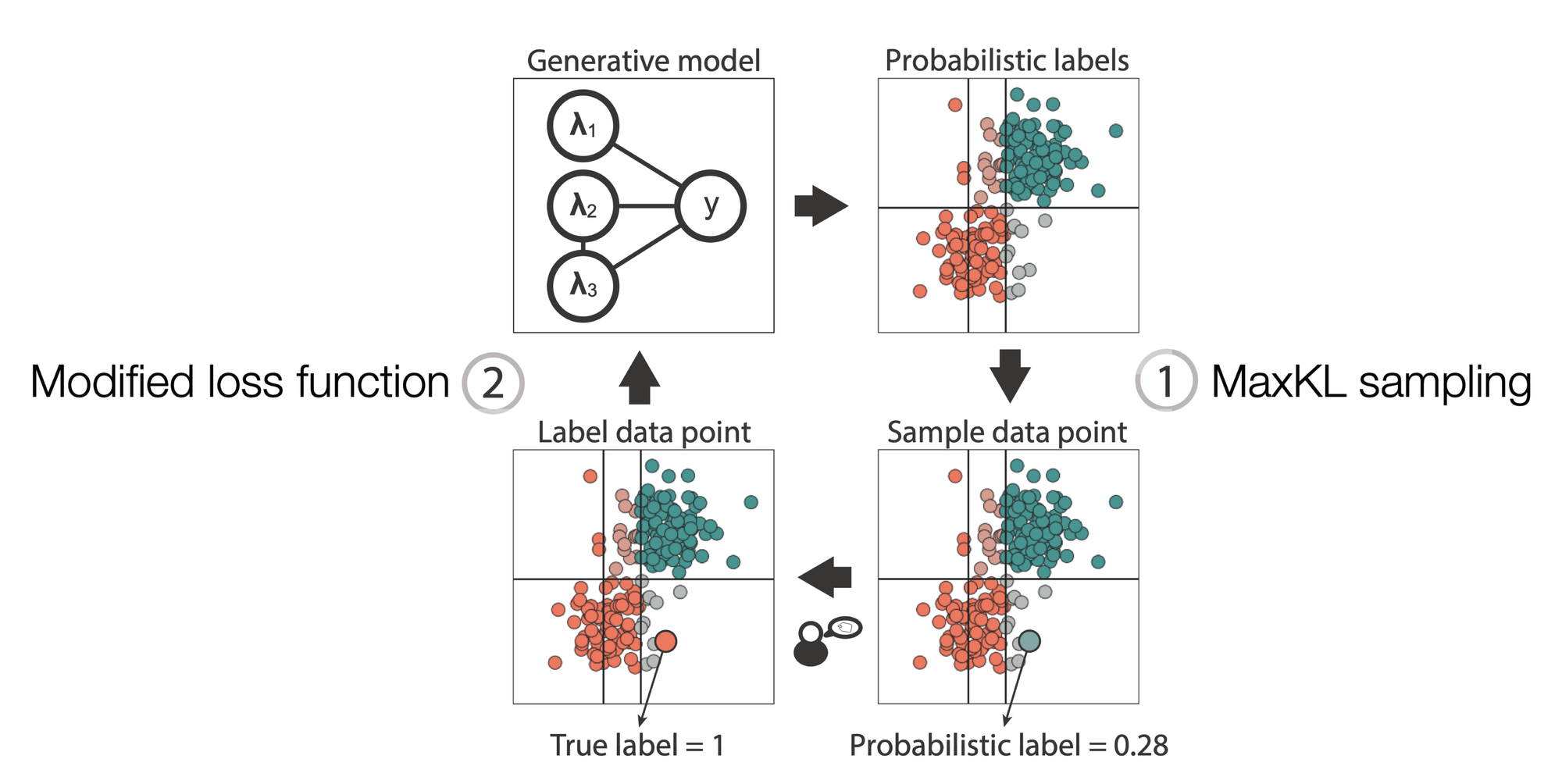
Within several iterations, the generative model adjusts, leading to a better classification boundary. See the following image:
To adjust the generative model in step 2, the weak supervision loss function is modified. The new objective looks like this:
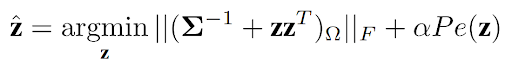
The first part comes from the objective of weak supervision itself, which is defined as a matrix completion problem. You can read more about this by clicking here.
The second part adds a penalty to the objective for any points that turn out to be mislabeled when comparing to the label obtained through active learning. This is implemented as the quadratic difference between the probabilistic label (a function of the label model parameters) and the expert label, as can be seen below:
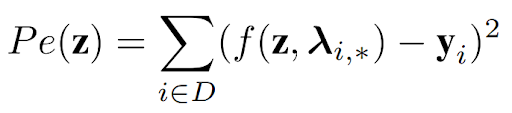
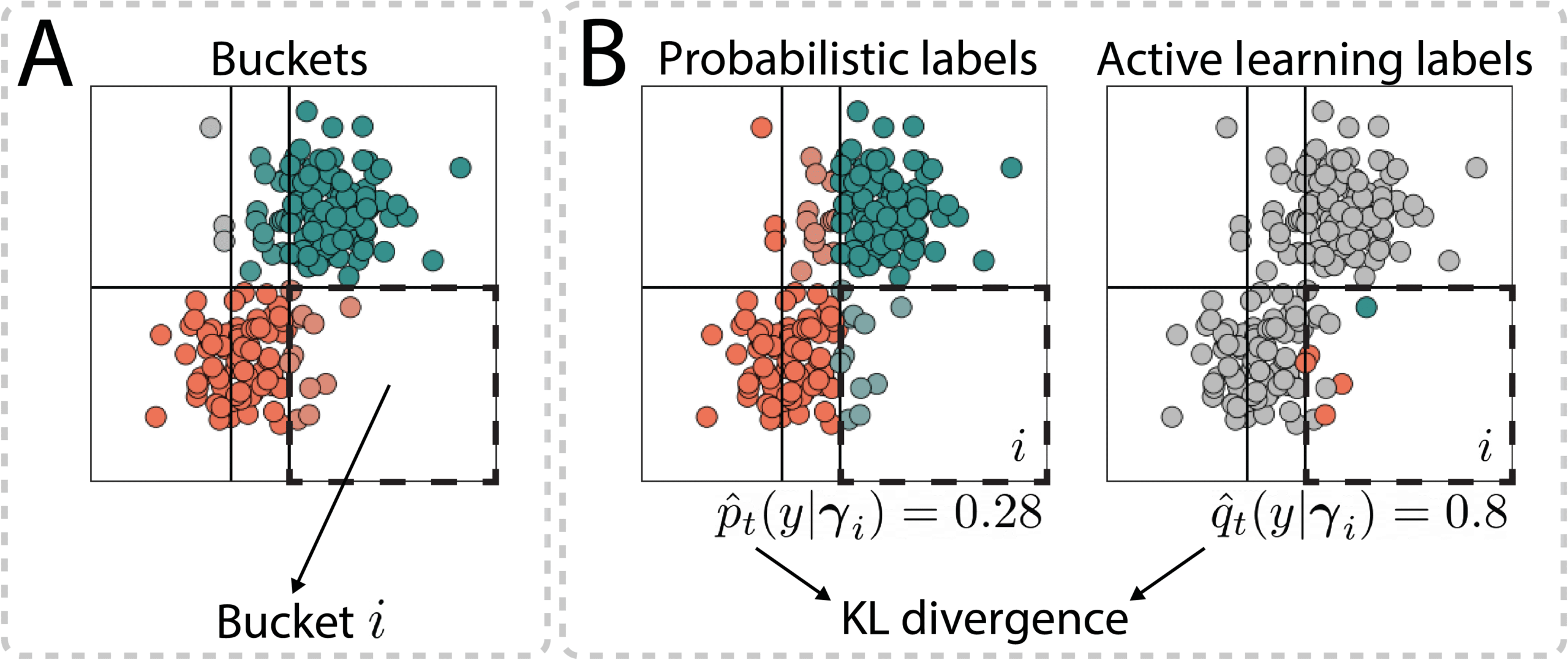
This modification allows us to improve the probabilistic labels, but it does not tell us which points to label. For this, the MaxKL query strategy was proposed. To see what this strategy does, first note that the data points in our set are divided into buckets, based on the different configurations of weak labels that are assigned to the data points (see part A in the image below). We take the probabilistic labels within each bucket as an estimate of the true class distribution. From the sampled labels from active learning, we get another estimate of the class distribution.
To decide which area to sample from, the Kullback-Leibler divergence between these two estimates is used (see part B below). If this value is relatively large for a particular bucket, it’s worth sampling more points. This will provide more feedback to adjust the generative model and get a better estimate of the class distribution.
Now that we’ve seen how the entire cycle of Active WeaSuL works, let’s look at some results on the simple artificial dataset first. The accuracy of Active WeaSuL is given by the dark blue lines in the figures below. It outperforms baseline approaches such as weak supervision by itself and active learning by itself. The improvement is also much faster than for a competing method in light blue.
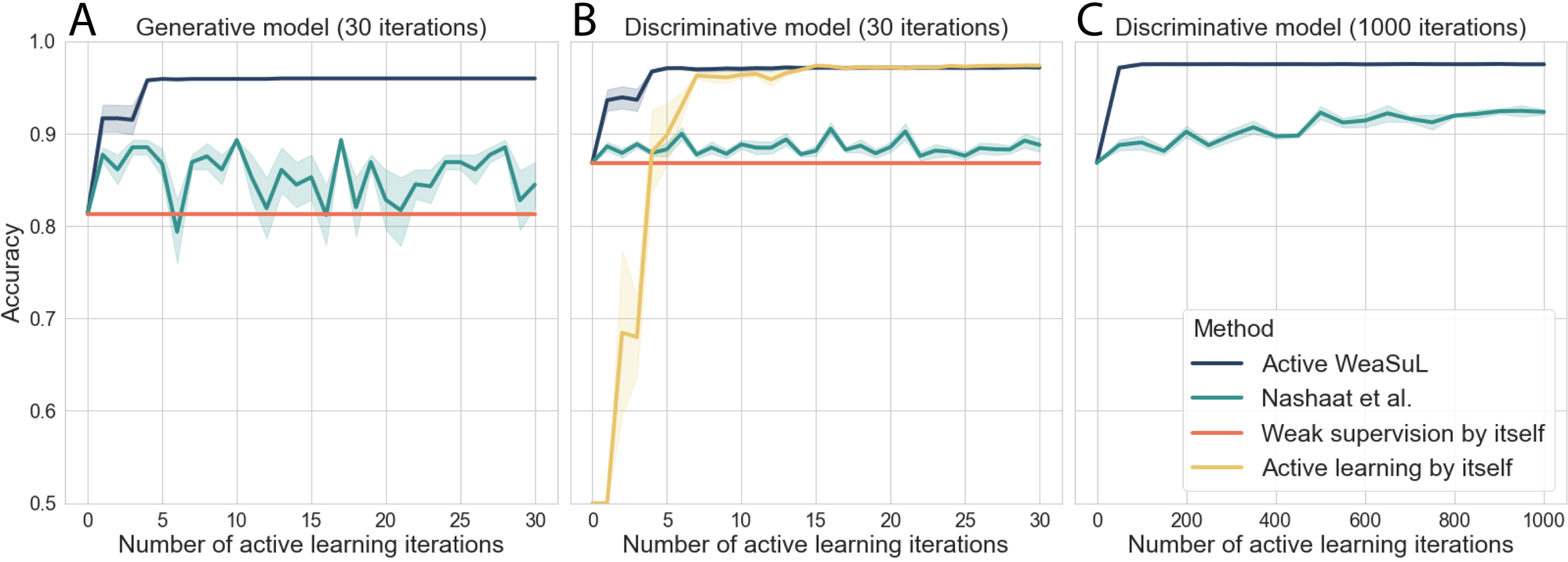
Similar insights were found on real-world problems, such as visual relation detection and spam detection. The first problem is about identifying the relationship between two objects in an image. For instance, in the image on the left below, the task is to label whether the relationship between ‘giraffe’ and ‘grass’ is ‘sitting on’ or not. In the results on this task, we see that with a bit more labeling resources, it might be better to use active learning by itself, as this can eventually lead to a better performance.
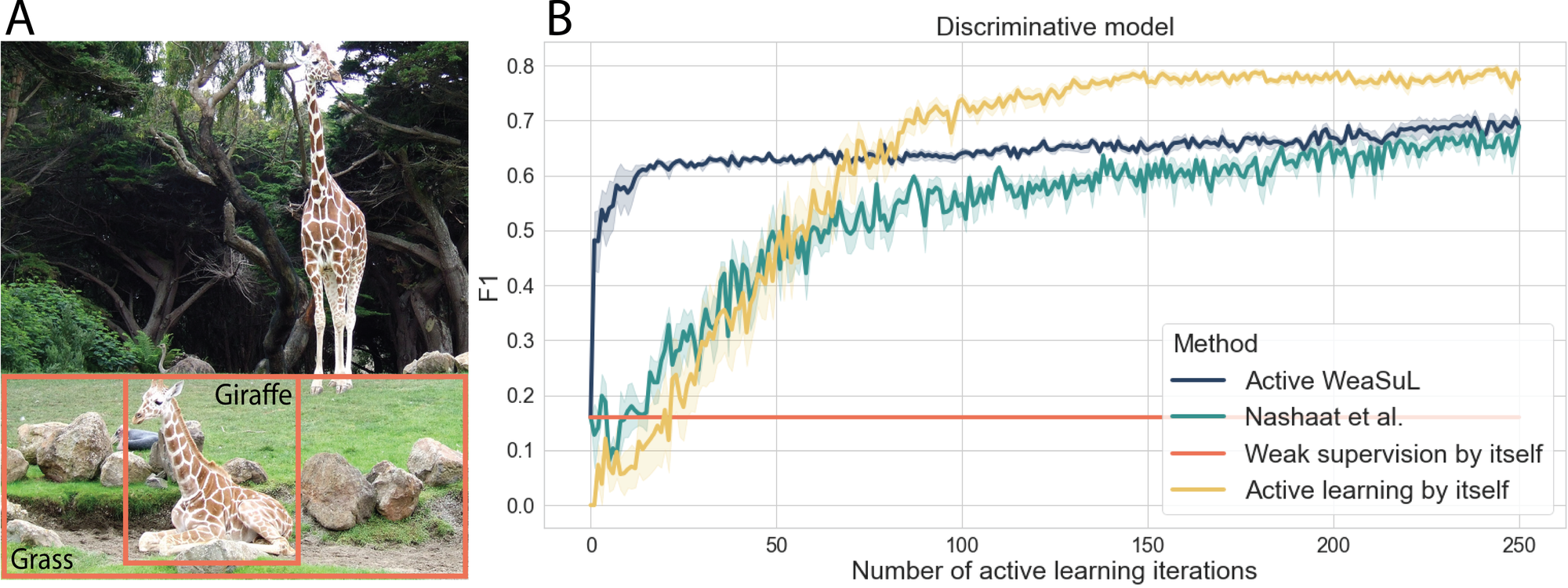
The results on different problems show that overall, the combination of active learning and weak supervision is helpful in getting a better performance with a small number of labeled points. That makes this approach ideal to use in situations where you have a very small labeling budget.
No terms found for this post.
No terms found for this post.

The gap between a compelling GenAI demo and a working production system is wider than most organisations expect. And the reason is almost never the technology.
So you centralise. The right call. One team manages agentic AI. They create rules, stop...

This blog is about getting full control of your data. And it is geared towards data platforms. However, a lot of the more generic remarks will hold up for other types of system environments also.

Modern AI tools have democratized software creation. With the concept of ‘vibe coding’ maturing to ‘agentic engineering’ and some powerful new plugins (or skills, MCP tools and CLI’s), full-stack development is now accessible to a much wider audienc...




