

When a machine learning model goes into production, it is very likely to be idle most of the time. There are a lot of use cases, where a model only needs to run inference when new data is available. If we do have such a use case and we deploy a model on a server, it will eagerly be checking for new data, only to be disappointed for most of its lifetime and meanwhile, you pay for the live time of the server. Now the cloud era has arrived, we can deploy a model serverless. Meaning we only pay for the computing we need and spinning up the resources when we need them. In this posts, we’ll define a serverless infrastructure for a machine learning model. This infrastructure will be hosted on AWS.
TL;DR
Deploy a serverless model. Take a look at: https://github.com/ritchie46/serverless-model-aws
For the code used in this blog post:
https://github.com/ritchie46/serverless-model-aws/tree/blog
Architecture
The image below shows an overview of the serverless architecture we’re deploying. For our infrastructure we’ll use at least the following AWS services:
- AWS S3: Used for blob storage.
- AWS Lambda: Executing functions without any servers. These functions are triggered by various events.
- AWS SQS: Message queues for interaction between microservices and serverless aplications.
- AWS ECS: Run docker containers on AWS EC2 or AWS Fargate.
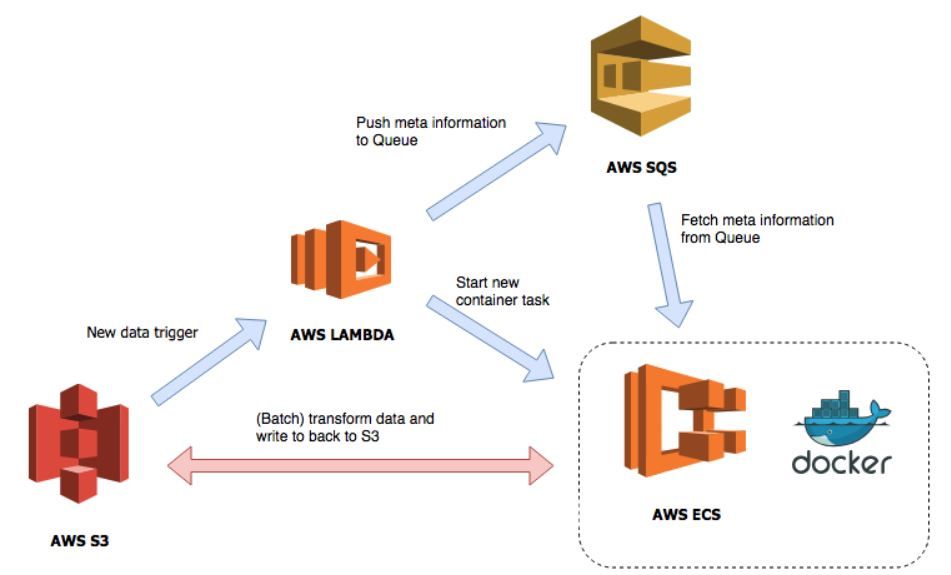
The serverless architecture The serverless application works as follows. Every time new data is posted on a S3 bucket, it will trigger a Lambda function. This Lambda function will push some metadata (data location, output location etc.) to the SQS Queue and will check if there is already an ECS task running. If there is not, the Lambda will start a new container. The container once started, will fetch messages from the SQS Queue and process them. Once there are no messages left, the container will shut down and the Batch Transform Job is finished!
Docker image
Before we’ll start with the resources in the cloud, we will prepare a Docker image, in which our model will reside.
Requirements
You’ll need to make sure you’ve got the following setup. You need to have access to an AWS account and install and configure the aws cli, and Docker. The aws cli enables us to interact with the AWS Cloud from the command line and Docker will help us containerize our model. To make sure we don’t walk into permission errors in AWS, make sure you’ve created admin access keys and add them to ~/.aws/credentials .
[default]
aws_access_key_id = <key-id>
aws_secret_access_key = <secret-key>File structure
For creating the Docker image we will create the following file structure. On the root of our project, we have a Dockerfile and the Python dependencies in requirements.txt .
project
| Dockerfile
| requirements.txt
| build_and_push.sh
|
|---src
| | batch_transform.py
| |
| |---cloudhelper
| | | __init__.py
| |
| |---model
| | | __init__.py
| | | transform.py Let’s go through the files one by one!
Dockerfile
In the Dockerfile we start from the Python 3.6 base image. If you depend on pickled files, make sure you use the same Python and library dependencies in the Dockerfile as the one you’ve used to train your model! The Dockerfile is fairly straightforward. We copy our project files in the image FROM python: 3 . 6 # first layers should be dependency installs so changes # in code won't cause the build to start from scratch. COPY requirements.txt /opt/program/requirements.txt RUN pip3 install -- no -cache-dir -r /opt/program/requirements.txt # Set some environment variables
ENV PYTHONUNBUFFERED=TRUE
ENV PYTHONDONTWRITEBYTECODE=TRUE
ENV PATH= "/opt/program: ${PATH} " `
# Set up the program in the image
COPY src /opt/program
COPY serverless/batch-transform/serverless.yml /opt/program/serverless.yml WORKDIR /opt/program
CMD python batch_transform.py
requirements.txt
The requirements.txt has got some fixed requirements for accessing AWS and reading YAML files. The other dependencies can be adjusted for any specific needs for running inference with your model.
d# always required
boto3
pyyaml
# dependencies for the custom model
numpy
scipy
scikit-learn
pandas
pyarrow
Interesting in reading the full blog?
For the full blog visit Ritchie's website!